My input stream is full of it: Fear and loathing and cheerleading and prognosticating on what generative AI means and whether
it’s Good or Bad and what we should be doing. All the channels: Blogs and peer-reviewed papers and social-media posts and
business-news stories. So there’s lots of AI angst out there, but this is mine.
I think the following is a bit unique because it focuses on cost, working backward from there. As for the
genAI tech itself, I guess I’m a moderate; there is a there there, it’s not all slop. But first…
The rent is too damn high
I promise I’ll talk about genAI applications but let’s start with money. Lots of money, big numbers! For example,
venture-cap startup money pouring into AI, which as of now apparently adds up to
$306
billion. And that’s just startups; Among the giants, Google alone
apparently plans
$75B in capital expenditure on AI
infrastructure, and they represent maybe a quarter at most of cloud capex. You think those are big numbers? McKinsey offers
The cost of compute: A $7 trillion race to scale data centers.
Obviously, lots of people are
wondering when and where the revenue will be to pay for it all. There’s one thing we know for sure:
The pro-genAI voices are fueled by hundreds of billions of dollars worth of fear and desire; fear that it’ll
never pay off and desire for a piece of the money. Can you begin to imagine the pressure for revenue that investors and
executives and middle managers are under?
Here’s an example of the kind of debate that ensues.
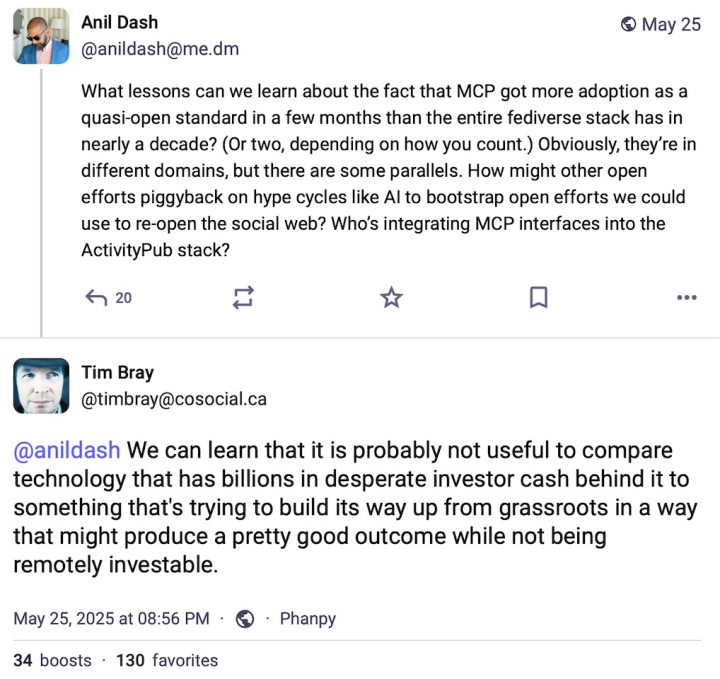
“MCP” is
Model Context Protocol, used for communicating between LLM
software and other systems and services.
I have no opinion as to its quality or utility.
I suggest that when you’re getting a pitch for genAI technology, you should have that greed and
fear in the back of your mind. Or maybe at the front.
And that’s just the money
For some reason, I don’t hear much any more about the environmental cost of genAI, the gigatons of carbon pouring out of the
system, imperilling my children’s future. Let’s please not ignore that; let’s read things like
Data
Center Energy Needs Could Upend Power Grids and Threaten the Climate and let’s make sure every freaking conversation about
genAI acknowledges this grievous cost.
Now let’s look at a few sectors where genAI is said to be a big deal: Coding, teaching, and professional
communication. To keep things balanced, I’ll start in a space where I have kind things to say.
Coding
Wow, is my tribe ever melting down. The pro- and anti-genAI factions are hurling polemical thunderbolts at each
other, and I mean extra hot and pointy ones. For example, here are 5600 words entitled
I Think I’m Done Thinking About genAI
For Now. Well-written words, too.
But, while I have a lot of sympathy for the contras and am sickened by some of the promoters, at the moment
I’m mostly in tune with Thomas Ptacek’s
My AI Skeptic Friends Are All Nuts. It’s long and (fortunately) well-written
and I (mostly) find it hard to disagree with.
it’s as simple as this: I keep hearing talented programmers
whose integrity I trust tell me “Yeah, LLMs are helping me get shit done.” The probability that they’re all lying or being
fooled seems very low.
Just to be clear, I note an absence of concern for cost and carbon in these conversations. Which is unacceptable. But let’s
move on.
It’s worth noting that I learned two useful things from Ptacek’s essay that I hadn’t really understood. First, the “agentic”
architecture of programming tools: You ask the agent to create code and it asks the LLM, which will sometimes
hallucinate; the agent will observe that it doesn’t compile or makes all the unit tests fail, discards it, and re-prompts. If
it takes the agent module 25 prompts to generate code that while imperfect is at least correct, who cares?
Second lesson, and to be fair this is just anecdata: It feels like the Go programming language is especially well-suited to
LLM-driven automation. It’s small, has a large standard library, and a culture that has strong shared idioms for doing almost
anything. Anyhow, we’ll find out if this early impression stands up to longer and wider industry experience.
Turning our attention back to cost, let’s assume that eventually all or most developers become somewhat LLM-assisted. Are
there enough of them, and will they pay enough, to cover all that investment? Especially given that models that are both
open-source and excellent are certain to proliferate? Seems dubious.
Suppose that, as Ptacek suggests, LLMs/agents allow us to automate the tedious low-intellectual-effort parts of our
job. Should we be concerned about how junior developers learn to get past that “easy stuff” and on the way to senior skills?
That seems a very good question, so…
Learning
Quite likely you’ve already seen Jason Koebler’s
Teachers Are Not OK, a
frankly horrifying survey of genAI’s impact on secondary and tertiary education. It is a tale of unrelieved grief and pain
and wreckage. Since genAI isn’t going to go away and students aren’t going to stop being lazy,
it seems like we’re going to re-invent the way people teach and learn.
The stories of students furiously deploying genAI to avoid the effort of actually, you know,
learning, are sad. Even sadder are those of genAI-crazed administrators leaning on faculty to become more efficient and
“businesslike” by using it.
I really don’t think there’s a coherent pro-genAI case to be made in the education context.
Professional communication
If you want to use LLMs to automate communication with your family or friends or lovers, there’s nothing I can say that will
help you. So let’s restrict this to conversation and reporting around work and private projects and voluntarism and so on.
I’m
pretty sure this is where the people who think they’re going to make big money with AI think it’s going to come from.
If you’re interested in that thinking,
here’s
a sample; a slide deck by a Keith Riegert for the book-publishing business which, granted, is a bit stagnant and a whole lot
overconcentrated these days. I suspect scrolling through it will produce a strong emotional reaction for quite a few readers here.
It’s also useful in that it talks specifically about costs.
That is for corporate-branded output. What about personal or internal professional communication; by which I mean emails and
sales reports and committee drafts and project pitches and so on? I’m pretty negative about this. If your email or pitch
doc or whatever needs to be summarized, or if it has the colorless affectless error-prone polish of 2025’s LLMs, I would
probably discard it unread.
I already found the switch to turn off Gmail’s attempts to summarize my emails.
What’s the genAI world’s equivalent of “Tl;dr”? I’m thinking “TA;dr” (A for AI)
or “Tg;dr” (g for genAI) or just “LLM:dr”.
And this vision of everyone using genAI to amplify their output and everyone else using it to summarize and filter
their input feels simply perverse.
Here’s what I think is
an important finding, ably summarized by Jeff Atwood:

Seriously, since LLMs by design emit streams that are optimized for plausibility and for harmony with the model’s
training base, in an AI-centric world there’s a powerful incentive to say things that are implausible, that are out of tune,
that are, bluntly, weird. So there’s one upside.
And let’s go back to cost. Are the prices in Riegert’s slide deck going to pay for trillions in capex?
Another example: My family has a Google workplace account, and the price just went up from $6/user/month to
$7. The announcement from Google emphasized that this was related to the added value provided by Gemini. Is $1/user/month gonna
make this tech make business sense?
What I can and can’t buy
I can sorta buy the premise that there are genAI productivity boosts to be had in the code space and maybe some other
specialized domains. I can’t buy for a second that genAI is anything but toxic for anything education-related. On the
business-communications side, it’s damn well gonna be tried because billions of dollars and many management careers depend on
it paying off. We’ll see but I’m skeptical.
On the money side? I don’t see how the math and the capex work. And all the time, I think about the carbon that’s poisoning
the planet my children have to live on.
I think that the best we can hope for is the eventual financial meltdown leaving a few useful islands of things that
are actually useful at prices that make sense.
And in a decade or so, I can see business-section stories about all the big data center shells that were never filled in,
standing there empty, looking for another use. It’s gonna be tough, what can you do with buildings that have no windows?



